AI Crawler Optimization: How Bots Like GPTBot & ClaudeBot Find You (2026)
Your website was visited by an AI crawler today. Probably hundreds of times.
Cloudflare reported AI crawlers were generating more than 50 billion requests per day across its network back in March 2025. A year later, the ecosystem has reshuffled twice.
Cloudflare Radar shows GPTBot just overtook ClaudeBot in May 2026 (11.97% vs 10.67%).
Bytespider more than doubled. Anthropic’s new Claude-SearchBot is appearing in publisher logs for the first time.
226 distinct AI crawler user agents catalogued. Most of which your robots.txt has never heard of.
If you’re still optimizing only for Google, you’re optimizing for a shrinking slice of how people actually find things.
This guide breaks down exactly how AI crawlers discover your website, what signals they care about, and how to optimize so your content gets cited inside ChatGPT, Claude, Perplexity, and Google’s AI Overviews, not just ranked on page one of a search nobody runs anymore.
What AI Crawler Optimization Actually Means
AI crawler optimization is the practice of making your website easily discoverable, parseable, and citable by the bots that power generative AI assistants and AI search engines.
It overlaps with SEO, but it’s not the same thing. Traditional SEO optimizes for a ranking algorithm that returns ten blue links.
AI crawler optimization optimizes for a retrieval system that returns a single synthesized answer and decides whether your brand is named in it.
Three things change in this shift:
- Crawlers behave differently: Some bots crawl to train models. Others crawl in real time to answer a user’s prompt.
- Signals matter differently: Clean structure, citable facts, and answerability beat keyword density.
- Measurement is harder: A citation inside ChatGPT doesn’t appear in Google Search Console, but it does show up as a referrer in your analytics, if you know where to look.
That last point is where most teams quietly lose. We’ll come back to it.
The Three Stages of AI Crawler Discovery
Every AI crawler interacts with your site in one of three modes. Optimizing for AI search means optimizing for all three.
Stage 1: Training Crawlers (Bulk Ingestion)
These bots collect content to train the underlying language model. They visit broadly, crawl deeply, and don’t drive any direct traffic.
Examples:
- GPTBot (OpenAI)
- ClaudeBot (Anthropic)
- CCBot (Common Crawl)
- Google-Extended (Google’s Gemini training).
Blocking them feels safe, they don’t send referrals, so why let them have your content?
The trade-off is brutal: if a model never trains on your brand, it never surfaces when someone asks it a question in your category six months later.
Stage 2: Real-Time Retrieval Crawlers (Live Citation Fetch)
These bots fetch a specific page in real time when a user asks an AI assistant a question, since the assistant needs fresh information to answer.
Examples:
- OAI-SearchBot and ChatGPT-User (OpenAI)
- Claude-SearchBot and Claude-User (Anthropic)
- PerplexityBot and Perplexity-User (Perplexity).
These are the highest-leverage crawlers in 2026.
A single visit from Perplexity-User means a real person, right now, is being shown an answer that may cite your page. Blocking them is essentially blocking your AI referral traffic at the source.
Stage 3: Agentic Crawlers (Task-Driven Visits)
These are newer and growing fast. When a user asks an AI agent to “book me a hotel under $200 in a specific area,” the agent fetches your site to read prices, availability, and structured data, then potentially completes the transaction.
You probably don’t have many of these yet. You will.
How AI Crawlers Actually Find Your Pages

Discovery for AI crawlers follows four paths. Most teams optimize for one and ignore the other three.
1. The Crawl Itself (Same as Google, Mostly)
AI crawlers still start with the basics: your sitemap, your internal links, your robots.txt directives, and external backlinks pointing to your URLs.
If your site is well-indexed by Google, you’re already partially discoverable.
Crawl frequency varies meaningfully:
- GPTBot revisits established sites every 1–7 days.
- PerplexityBot every 1–3 days for active sites.
- ClaudeBot every 3–14 days, with crawl rates roughly doubling.
2. Training Data Recall
When you ask ChatGPT, “What’s a good privacy-first analytics tool?” and it names three brands, those names came from training data, not a live crawl.
Getting into training corpora is a long-tail game played over months, through citations, mentions on high-authority sites, GitHub references, Reddit threads, and Wikipedia.
3. Live Search Index Queries
Most AI assistants now route real-time questions through a search index (Bing for ChatGPT, Google for Gemini, their own index for Perplexity).
Your traditional SEO ranking still matters here. If you don’t rank on Bing, ChatGPT’s web search probably won’t find you.
4. Direct URL Hints (llms.txt and Structured Markers)
The newest layer. llms.txt is a plain-text Markdown file at the root of your site that proposes a curated, AI-friendly map of your most important content.
Proposed by Jeremy Howard in 2024, it’s been adopted by Anthropic, Vercel, Hugging Face, Stripe, and Mintlify.
Honest disclosure: no major AI provider has officially confirmed that llms.txt influences rankings or citations yet, and Semrush has reported no correlation between implementing it and improved AI search performance.
But it costs roughly 30 minutes to create and risks nothing. If the standard takes hold, you’re already in.
The Optimization Stack: What Actually Moves the Needle
Here’s the practical playbook, ordered by impact.
Allow the Right Crawlers
The single biggest mistake is a default SEO plugin or CDN rule that blocks AI crawlers without anyone realizing. Audit your robots.txt today. At minimum, explicitly allow:
The retrieval bots (ChatGPT-User, Perplexity-User, Claude-User) are the non-negotiables. Block these, and you’ve turned off your AI referral pipeline.
Write for Extractive Reading
LLMs don’t read; they extract. Structure your content so the model can lift one clean, citable chunk and drop it into an answer.
- Lead each section with a direct, declarative answer to a likely question
- Use H2s and H3s as literal questions when appropriate (“What is X?”, “How does Y work?”)
- Keep paragraphs short (2–4 sentences)
- Include concrete numbers, dates, and named entities. These are what models prefer to cite
- Add a TL;DR or summary block near the top
Build Citation-Worthy Authority Signals
Models cite pages that look authoritative. The signals are unsexy but consistent:
- Original data and proprietary research
- Named authors with verifiable credentials
- Clear publication and update dates
- Outbound citations to primary sources
- A real “About” page with a real human or team
Implement llms.txt (Low Effort, Maybe High Reward)
Create /llms.txt at your domain root with a Markdown summary of your site’s purpose and links to your highest-value pages. Even if no model uses it today, you’ve spent half an hour insuring against the possibility that they will tomorrow.
Don’t Forget Bing
ChatGPT’s web search runs on Bing. If your Bing ranking is poor, your live ChatGPT citation surface is likely poor as well.
Submit your sitemap to Bing Webmaster Tools. It’s still the most underused leverage in AEO.
The Measurement Problem (And Why Most Teams Are Flying Blind)

Here’s the part almost nobody talks about: you can configure robots.txt perfectly, ship llms.txt, structure every page for extraction, and have no idea whether any of it is working.
AI crawlers don’t report back. Google Search Console doesn’t show you Perplexity referrals.
ChatGPT doesn’t email you when it cites your page. The only way to know if your AI crawler optimization is paying off is to watch your traffic data for two specific signals:
- Crawler hits in your server logs, or analytics: is GPTBot actually reaching your high-value pages, or is something blocking it?
- Referrer traffic from AI assistants: Are visits from chat.openai.com, perplexity.ai, claude.ai, and copilot.microsoft.com going up, flat, or invisible?
This is exactly where a privacy-first analytics tool like Vemetric earns its place in the AEO stack.
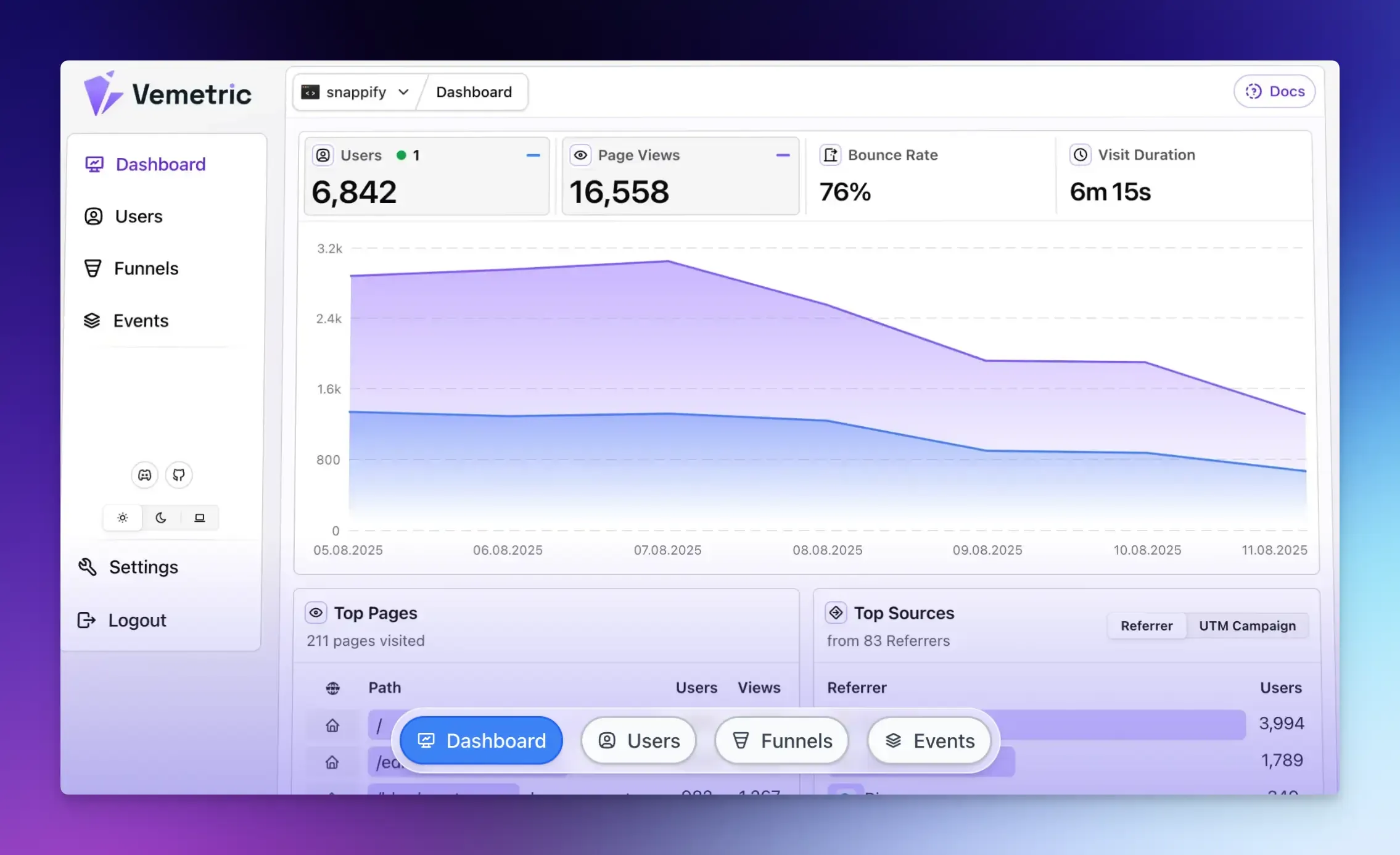
It surfaces top referrers, including ChatGPT and other AI assistants, without requiring cookies or consent banners that suppress your data.
You see which AI sources are sending real users to your site, which pages they land on, and what those users do next.
Setting up AI crawler optimization without measurement is like running paid ads with the conversion pixel turned off. The work is happening; you can’t see the result.
A practical measurement loop looks like this:
- Weekly: Check your top referrers report. Are AI assistant domains appearing? Trending up?
- Monthly: Scan server logs (or your analytics tool’s bot section) for GPTBot, ClaudeBot, and PerplexityBot. Are they hitting your money pages?
- Quarterly: Run 20–30 category-relevant prompts in ChatGPT, Claude, and Perplexity. Does your brand get cited?
If referrals are flat and crawlers aren’t visiting, your robots.txt or CDN is probably the problem.
If crawlers visit but no referrals come back, your content isn’t getting cited; that’s a content quality problem, not an access problem. Diagnosis only works when you can see both layers.
Common AI Crawler Mistakes to Avoid
A few patterns to watch for:
- Wildcard blocks in your CDN: Cloudflare, Fastly, and others have aggressive bot-blocking presets that catch AI crawlers along with scrapers. Audit them.
- Trusting llms.txt as access control: It isn’t. Crawlers can read it and ignore it. Use robots.txt and your WAF for access decisions.
- Optimizing without tracking referrers: If you can’t see ChatGPT traffic in your analytics, you can’t know what’s working. Pick an analytics tool that surfaces this cleanly.
Final Words
AI crawler optimization isn’t a magic checklist.
It’s three things stacked together: technical access (let the right bots in), content structure (make your pages extractable), and measurement (actually see what’s happening).
Most of the public conversation focuses on the first two.
The third is what separates teams that guess from teams that know.
Allow the crawlers. Structure your content for retrieval. Then watch your referrer data weekly, because that’s the only place AI search citations show up.
FAQs
AI crawler optimization is the practice of configuring your website so AI bots like GPTBot, ClaudeBot, and PerplexityBot can discover, access, and cite your content. It includes robots.txt configuration, content structure, structured signals like llms.txt, and tracking AI referrer traffic in analytics.
Google’s crawler indexes pages for a ranked list of search results. AI crawlers fall into three categories: training crawlers (bulk content ingestion for model training), real-time retrieval crawlers (fetching pages live to answer a user’s prompt), and agentic crawlers (visiting pages to complete tasks on behalf of a user). They behave differently, visit different pages, and reward different signals.
Ready to understand your users?
Start tracking